汇总
- cache —— 预计算
- 分割成子区域
- 减少采样次数
- 加快积分过程
PlenOctrees for Real-time Rendering of Neural Radiance Fields
Info
- 会议:ICCV
- 年份:2021
Method
- 训练一个 NeRF-SH 网络
- 将原来的 color 输出改为了球谐函数
- 球谐函数可以用来表示 view-dependent 的表面
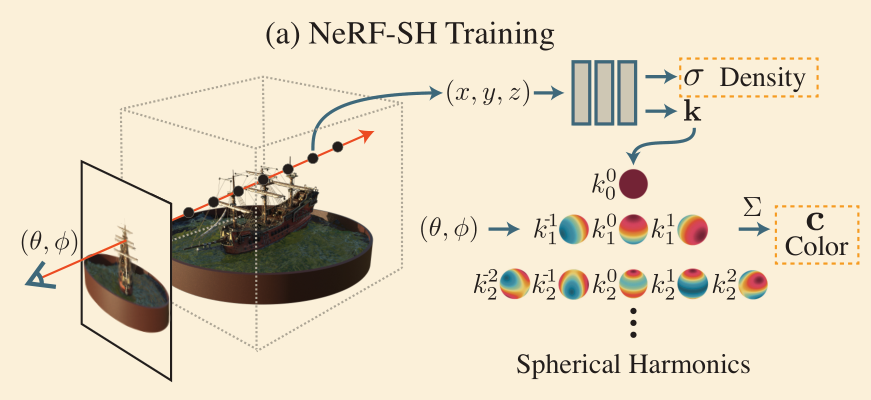
- 把该网络转化成一个八叉树
- 对场景中的点进行采样,根据网络预测的 density 构建八叉树
- 叶结点中存放当前位置的球谐函数系数
- 构建好八叉树结构后,利用训练样本优化叶结点中的值(Fine-tuning)
- 渲染时不需要经过网络,只需要访问叶结点
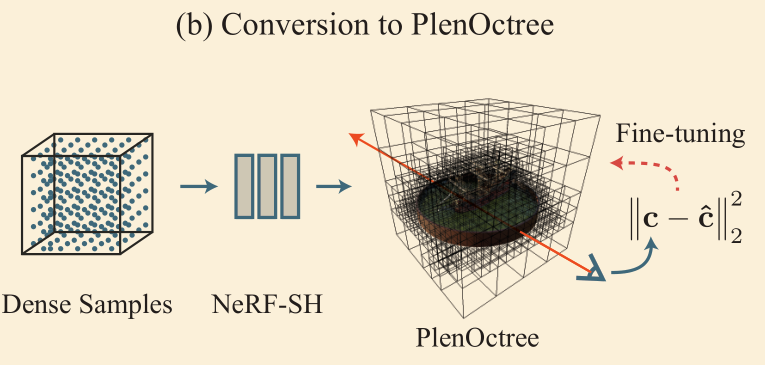
- 对场景中的点进行采样,根据网络预测的 density 构建八叉树
Result
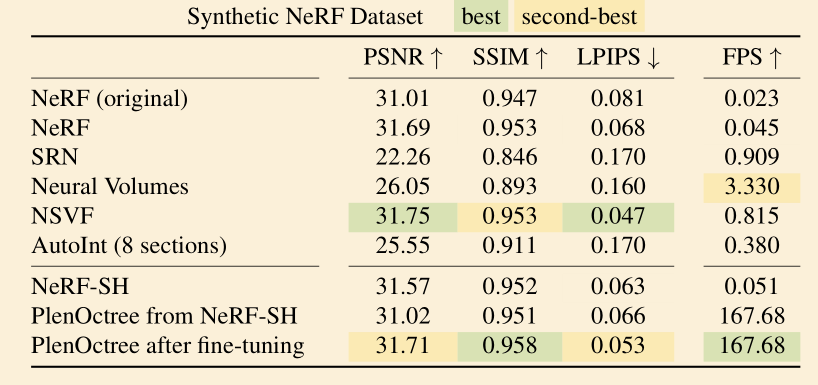
- 渲染速度大概是原版 NeRF 的 3000 倍
AutoInt: Automatic Integration for Fast Neural Volume Rendering
Info
- 会议:CVPR
- 年份:2021
Method
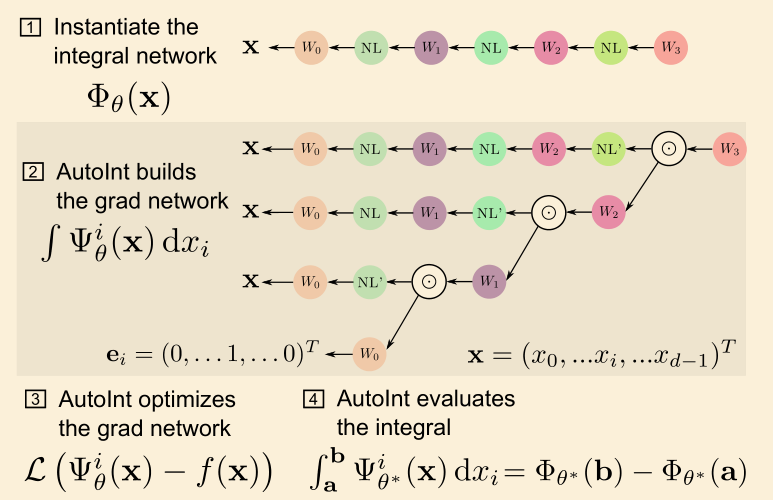
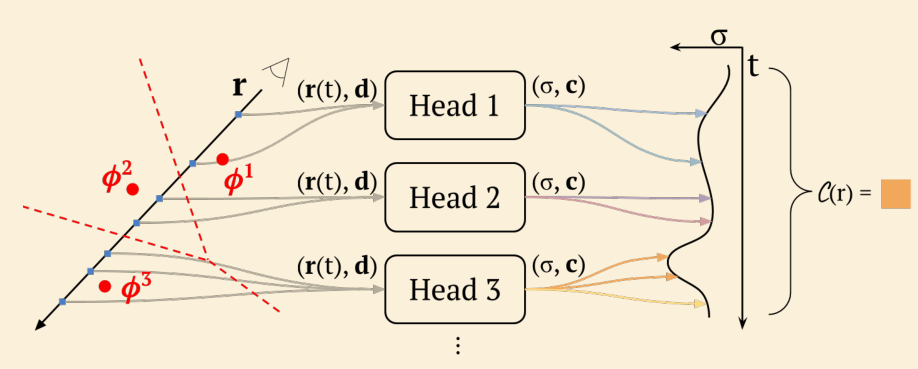
- 用两个神经网络来求解 volume rendering 的积分过程
- integral network 用来表示积分结果
- grad network 用来拟合被积分函数
- 二者共用参数
- 训练 NeRF 时,优化 grad network
- 预测时,将 grad network 整合成 integral network 以预测积分结果
- 将光线路径分成若干 sections,分段进行积分
Result
- 渲染速度大概是原版 NeRF 的 10 倍
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
Info
- 会议:CVPR
- 年份:2021
Method
- DeepSDF
- 额外输入一个形状编码,以学习不同形状的物体

- DeepSDF 存在的问题
- 无论形状是简单还是复杂,都使用同样的 MLP
- 不支持 LOD
- 本文思路:使用一系列特征向量,而不是只使用一个
- 这些特征向量用八叉树维护
- 物体的 LOD 由八叉树的深度决定
- 由于使用了一系列特征向量,每个特征向量表达的是较小范围内物体表面处的形状
- 因此,用一个很小的 MLP 就可以很好地拟合,从而加速渲染

Result
- 渲染速度大概是原版 DeepSDF 的 50 - 100 倍

Neural Sparse Voxel Fields
Info
- 会议:NeurIPS
- 年份:2020
Methods
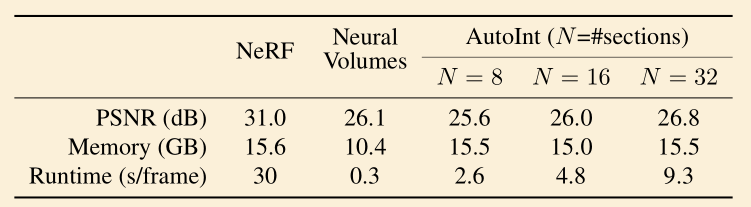
- 思路:将 NeRF 场景表达为 voxels,剔除那些空的 voxels
- 训练
- 初始化网格,训练 NeRF,统计每个体素内的密度,若小于阈值则去掉
- 将剩下的 voxels 细分成 8 个 sub-voxel
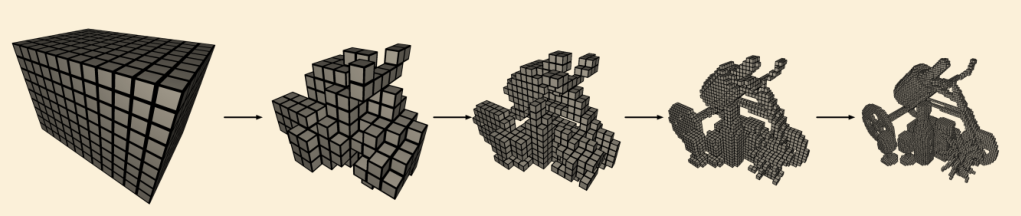
- 渲染
- 在 voxels 外面不用访问 NeRF
- 在 voxel 内部做 ray marching,采样点处访问 NeRF
Result
- 渲染速度大概是原版 NeRF 的 40 倍

DeRF: Decomposed Radiance Fields
Info
- 会议:CVPR
- 年份:2021
Method
- 思路:将场景分割为几个部分,每个部分用一个小一点的 NeRF 来表达
- 分割:Voronoi diagram
- 渲染:使用画家算法,先渲染离相机较远的部分
Result
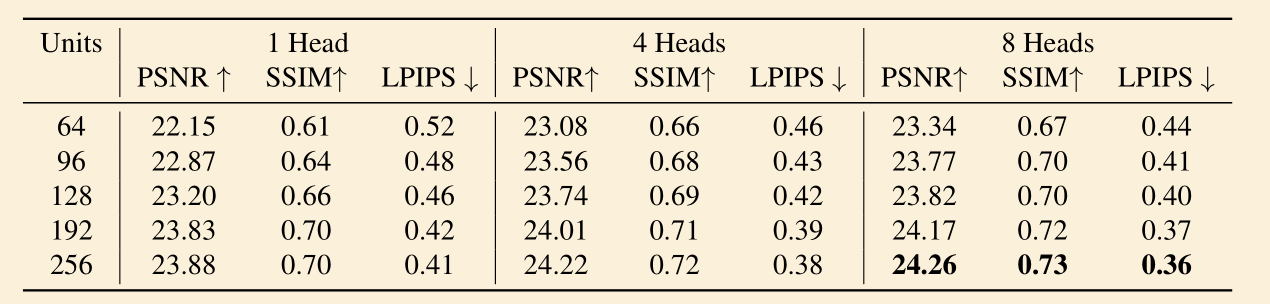
- 论文只比较了不同参数下自己的效果,未与其他方法进行比较
- 结果分析中,着重分析了图像质量
- units -> NeRF 中每一层的神经元个数,heads -> 分割的块数
DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks
Info
- 会议:EGSR(Eurographics Symposium on Rendering)
- 年份:2021
Method
思路:添加一个网络用于预测最佳采样位置,这样 NeRF 只需极少采样点就能得到结果
定义 view cell
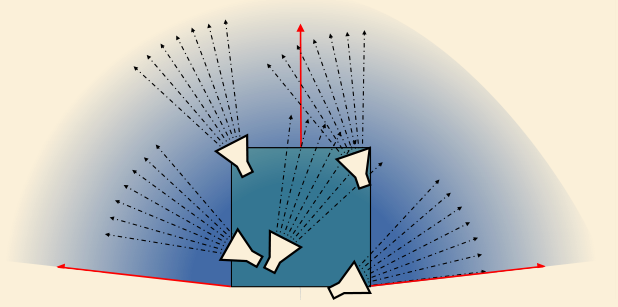
- bounding box + 主方向 + 最大视角范围
- 可以用来分割大场景
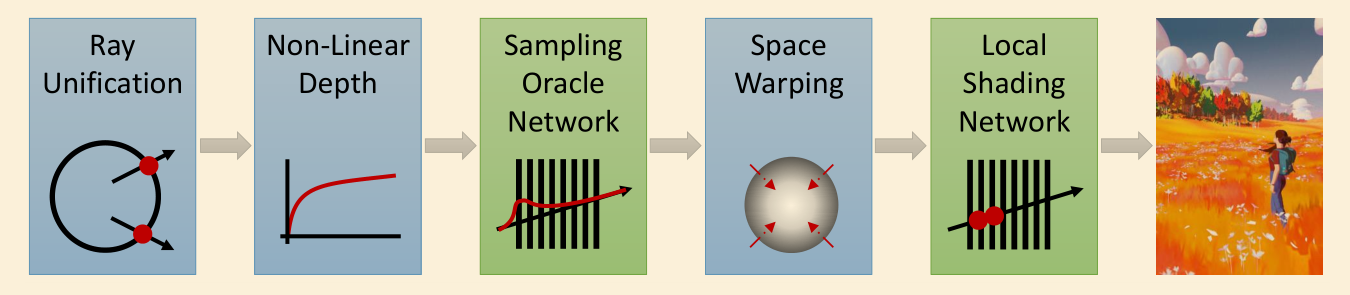
- 将一个 view cell 里方向相同的光线映射到同一 origin
- 将深度转换到非线性的空间,即采样时使用非线性的深度值
- 由 Oracle network 预测深度的位置
- 将预测的位置映射到 view cell 里
- 在 NeRF 中采样这些位置的结果,获得最后的像素值
Result
渲染速度提升大概 50 倍
FastNeRF: High-Fidelity Neural Rendering at 200FPS
Info
- 会议:ICCV
- 年份:2021
Method
将 NeRF 分解为两个网络
- position 网络输出一组 radiance
- direction 网络输出一组 weight
最终结果为两个网络输出的乘积
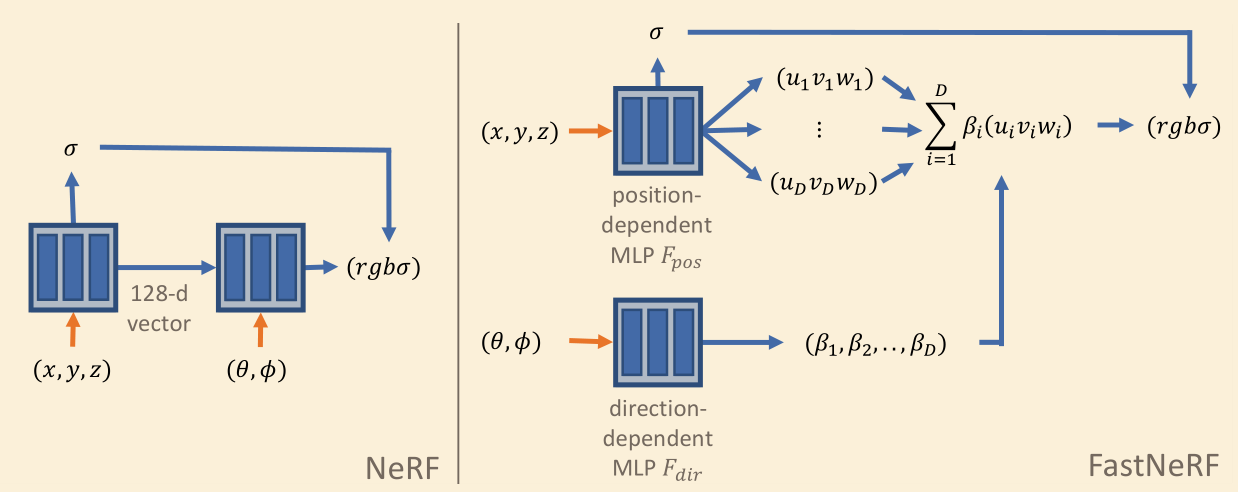
加速 —— cache
- 在包围盒内,均匀地取若干个采样点,每个采样点上取一组相机方向
- 将所有采样点的网络输出储存下来
- 渲染时,在这些值里面进行插值
Result
- 渲染速度大概是原版 NeRF 的 3000 倍
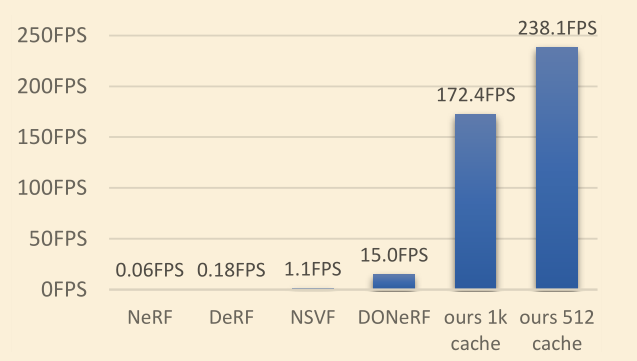
然而需要大量的 cache 空间

KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
Info
- 会议:ICCV
- 年份:2021
Method
将场景均匀分割,每个小块对应一个简化版的 NeRF
简化版的网络结构
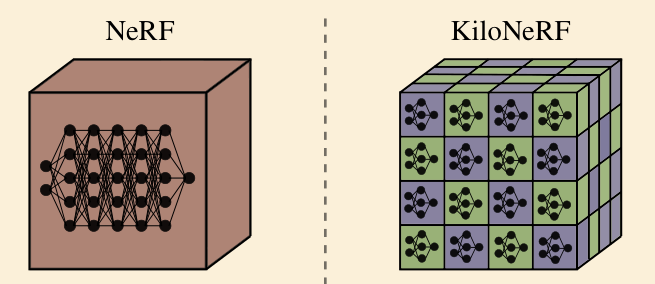
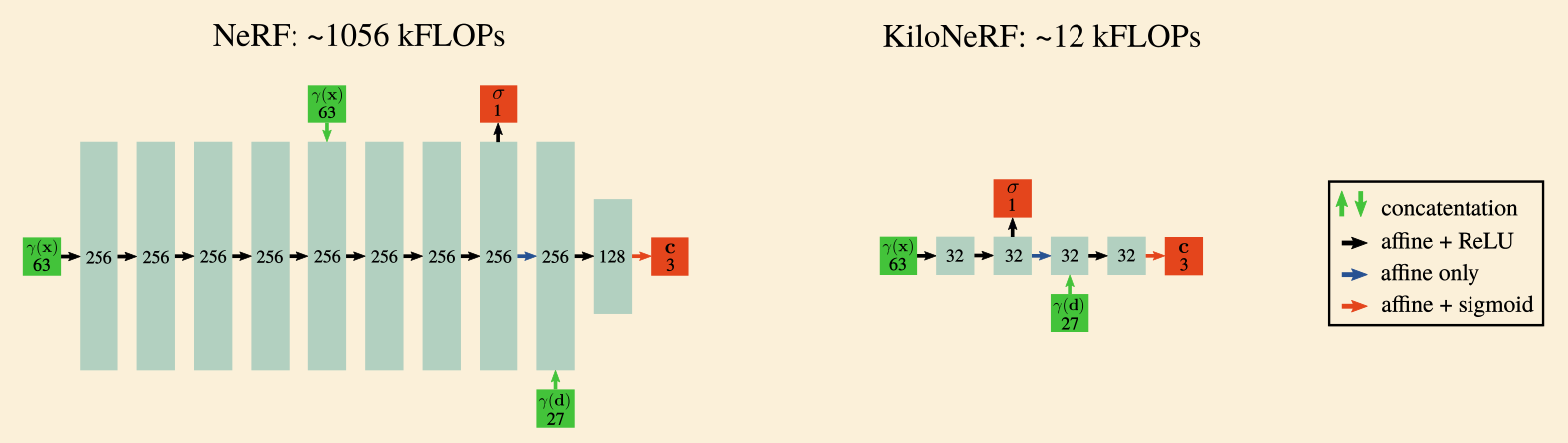
Result
渲染速度大概是原版 NeRF 的 2000 多倍

Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
Info
- 会议:NeurIPS
- 年份:2021
Method
- 引入光场,使得渲染时只需要采样一次
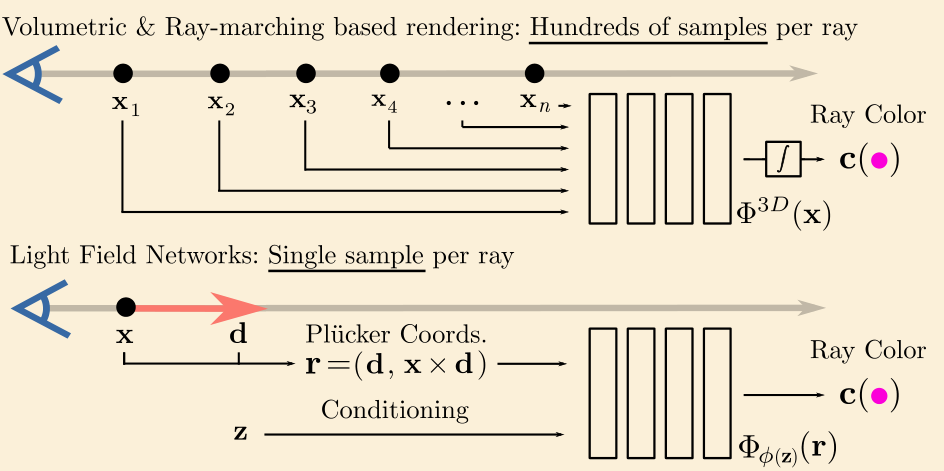
- 输入
- 6 维的 Plücker 坐标,用来表示某一条光线
- 对场景编码得到的特征向量 z
- 输出
- 当前光线对应的颜色值
Result
- 渲染时间比 volume rendering 减少了 3 个数量级
